Feature Flags: Transform Your Product Development Workflow
by Ben Nadel
Copyright © 2024 Ben Nadel
All rights reserved. No portion of this book may be reproduced in any form without prior permission from the copyright owner of this book.
Dedication
Dedicated to my wife, who tells me that I can do anything;
And, to my dog, who loves me unconditionally.
Table of Contents
- Foreword
- Contributors
- Acknowledgments
- Who Should Read This Book
- Code Samples
- Caveat Emptor
- Of Outages and Incidents
- The Status Quo
- Feature Flags, an Introduction
- Key Terms and Concepts
- Going Deep on Feature Flag Targeting
- The User Experience (UX) of Feature Flag Targeting
- Types of Feature Flags
- Life-Cycle of a Feature Flag
- Use Cases
- Server-Side vs. Client-Side
- Bridging the Sophistication Gap
- Life Without Automated Testing
- Ownership Boundaries
- The Hidden Cost of Feature Flags
- Not Everything Can Be Feature Flagged
- Build vs. Buy
- Track Actions, Not Feature Flag State
- Logs, Metrics, and Feature Flags
- Transforming Your Company Culture
- People Like Us Do Things Like This
- Building Inclusive Products
- An Opinionated Guide to Pull Requests (PRs)
- Removing the Cost of Context Switching
- Measuring Team Productivity
- Increasing Agility With Dynamic Code
- Product Release vs. Marketing Release
- Getting From No to Yes
- What If I Can Only Deploy Every 2 Weeks?
- I Eat, I Sleep, I Feature Flag
Foreword
I'm not sure why, out of all the ColdFusion Summit 2021 recordings, the first one I picked to watch was Ben Nadel's presentation on feature flags. I had never heard the term before, but I've known Ben for years—he always has great information to bring to our developer community. Not even halfway through the presentation, it was like getting hit by a lightning bolt—this is what I need! I couldn't wait to implement feature flags for the clients I currently had. I went right to work making that happen; and it was a huge success. A couple of years later, I found myself giving my own presentation on feature flags at CF Summit.
Feature flags can be that life-changing for a developer. Think of the first time you learned about source control and all the problems it solved. Feature flags are like that. They are deceptively simple; but the more your development revolves around them, the more things you find they can do for you. They are a big hit with clients, too, especially those who have often seen bugs make it to production. Helping me do my job better and letting my clients think I'm a genius in the process?! Sign me up!
Ben Nadel brings his years of experience to the table in this new book, explaining what feature flags are and how they work in very clear, simple-to-understand instructions and sample code. You'll find best practices, solutions to common problems, and ideas for different ways in which you can use flags in your own projects—as well as what not to do. This book is a treasure trove of information that is otherwise very hard to come by on the topic. So enjoy your journey into this new world of feature flags. You will never be the same again!
— Mary Jo Sminkey
Mary Jo Sminkey is a Senior Web Developer at CFWebtools and a frequent presenter at ColdFusion conferences with over 25 years of experience.
Contributors
About the Author
Ben Nadel is a full-stack software engineer, writer, podcaster, and occasional speaker with a passion for web development that spans over two decades. His journey in the tech industry began in the late 90s; and, since 2006, he's been using his blog to learn in public, writing short-form articles that try to balance maturity, curiosity, and vulnerability. This is his first foray into long-form writing.
For the last 12 years, Ben has been building an online collaboration platform for design teams. This experience has instilled in him a profound appreciation for customer-focused design and a commitment to inclusive development practices.
He currently lives in Rhinebeck, New York with his wife (Mary Kate) and his adorable Yorkie (Lucy).
- LinkedIn: www.linkedin.com/in/bennadel
- Blog: www.bennadel.com
About the Reviewer
Adam Cameron is a seasoned full-stack software engineer and polyglot programmer with a meticulous eye for detail and a deep appreciation for best practices. Having spent more than 20 years in the tech industry, Adam is widely known for his no-nonsense communication style and his relentless efforts to mentor other engineers both on his blog and in a variety of web development forums.
Adam is a Test-Driven Development (TDD) evangelist and agrees with absolutely nothing that Ben says is in the chapter, Life Without Automated Testing.
- LinkedIn: www.linkedin.com/in/adamcameron1
- Blog: blog.adamcameron.me
About the Cover Designer
Emily Nadel is a multi-medium graphic artist. Educated at Boston University and the School of Visual Arts (SVA), Emily has spent her life deconstructing the human experience through pen, paint, and pixels. In the last 15 years, Emily has worked in landscape architecture and urban design through 3D and 2D digital representation; and has been reshaping the physical world as the Director of Graphic Design at MPFP in New York City.
- LinkedIn: www.linkedin.com/in/emily-nadel-3664b720
Acknowledgments
I can't write a book about the way in which feature flags revolutionize product development without giving high praise to the world-class engineers who helped me explore these ideas and identify which patterns work and which patterns don't. Thank you so much (in alphabetical order):
- David Bainbridge
- David Epler
- JD Courtoy
- Joshua Siok
- Robbie Manalo
- Scott Van Hess
- Shawn Grigson
- Gabriel Zeck
And, of course, I must thank my managers who generously granted me the freedom to try new things even when it meant going a little rogue, being a little dangerous, and—sometimes—getting them in a little bit of trouble. Thank you so much for your support and mentoring (in alphabetical order):
The years that I spent on the Rainbow Team were nothing short of transformative.
Who Should Read This Book
I have written this book for any team that is building customer-facing software; and is keen to build a more stable, more rewarding product for said customers. This might be in the context of a consumer product (B2C), an enterprise product (B2B), or an internal intranet in which your coworkers are your "customers".
If you've ever been frustrated by the pace of development, this book is for you. If you've ever felt disconnected from your organization, your mission, or your customers, this book is for you. If you've ever imagined that there must be a better way to approach product development, I can tell you there is; and, this book is for you.
Feature flags are primarily an engineering tool. As such, I'm speaking primarily to my fellow engineers. I believe that we engineers inhabit a uniquely potent role within the organization. We exist at the nexus of design, form, function, user experience, and platform stability. We communicate with Support engineers, Sales associates, Designers, Product Managers, Project Managers, Technical writers, and customers. This centrality gives us an opportunity to break down barriers and help heal the cultural problems that plague our companies and our productivity.
That said, this book holds value for non-engineers. Product development is a collaborative process. And, we build our best products when we work together in harmony. The sooner we can all start moving in the same direction with the same priorities, the sooner we can start shipping products with confidence and without fear. This book will help you reset unhealthy organizational expectations, build psychological safety and, show you a product development strategy that is both iterative and inclusive.
There are no prerequisites here. Your team doesn't have to be a certain size or reach a certain level of engineering complexity before you start using feature flags. In fact, feature flags help bridge the sophistication gap between small, scrappy teams and large, vertically integrated teams. All that you really need is a desire to build better products. And, a belief that great things will happen when you starting operating from a place of love and generosity.
If you're in the early stages of product formation and you don't yet have customers, feature flags won't help you all that much. They can still aide in feature optimization and serve to bootstrap certain feature modules. But, until you have customers, your chosen approach to product development is simply less meaningful.
Of course, you should be aiming to pull customers into your development process as soon as possible. Feature flags will let you do this safely and effectively.
Feature flags work particularly well for web-based software (my area of expertise); which is where this book is focused. But, I have seen other teams use feature flags with great success in both desktop software and mobile apps.
Code Samples
The code samples in this book predominantly consist of ColdFusion Markup Language (CFML). I chose CFML because it has a large overlap with other languages; so, the syntax should feel very familiar to most programmers. But, it has the added benefit of optional named-arguments and type-checking in its method invocation, which allows me to more clearly articulate how data is being passed-around.
CFML also has both a Script-based syntax and a Tag-based syntax, which allows the same language to be used seamlessly in both View-template rendering and back-end business logic. For example, I can use a traditional if statement for Script-based control flow and a <cfif> tag to conditionally render HTML blocks.
One of the biggest differences between CFML and other languages is that arrays are 1-based. Meaning, the first index is 1, not 0.
CFML is a server-side programming language. And the vast majority of the code in this book represents server-side logic. But, I also have references to HTML, JavaScript, and Angular. And, I do use JSON quite heavily to represent a feature flag's configuration.
Ultimately, feature flags are not language-specific. They embody a programming and product development paradigm that can be applied in any language. And, each language is going to have its own implementation details. As such, you should feel free to treat the code in this book as pseudo code that is provided for illustrative purposes.
Caveat Emptor
I have opinions. Often, these opinions are strong; and, in most cases, these opinions are strongly held. But, they are just my opinions. In this book, I will speak with an air of authority because I believe deeply in what I am saying based on what I have seen: a team transformed. But, what I am saying is based on my own experience, context, and organizational constraints. What I say may not always apply perfectly to you and your situation.
You are a discerning, creative person. You are here because you're enrolled in the work of building better products; of building more effective teams; and, of delivering more value to your customers. Do not let that creativity take a back seat as you read this book. Be critical, but open-minded; question my assertions, but do not dismiss them out of hand.
Feature flags are a deceptively simple concept. It can be hard to understand the extent of the impact they have on your team because the implications aren't only technical. If all you learn from this book is how to use feature flags as a means to control flow within your software, this book will be worth reading. However, the true value of what I'm sharing here lies in the holistic cultural change that feature flags can bring to every part of your product development life-cycle.
This book does not represent an all-or-nothing approach to product development. But, I do believe that the more you take from this book, the more you will get.
Of Outages and Incidents
I used to tell my people: "You're not really a member of the team until you crash production".
In the early days of the company, crashing production—or, at least, significantly degrading it—was nothing short of inevitable. And so, instead of condemning every outage, I treated each one like a rite of passage. This was my attempt to create a safe space in which my people could learn about and become accustomed to the product.
What I knew, even then, from my own experience is that engineers needed to ship code. This is a matter of self-actualization. Pushing code to production benefits us just as much as it benefits our customers.
But, when our deployments became fraught, my engineers became fearful. They began to overthink their code and under-deliver on their commitments. This wasn't good for the product. And, it wasn't good for the team. Not to mention the fact that it created an unhealthy tension between our Executive Leadership Team and everyone else.
The more people we added to our engineering staff, the worse this problem became. Poorly architected code with no discernible boundaries soon lead to tightly coupled code that no one wanted to touch let alone maintain. Code changed in one part of the application often had a surprising impact in another part of the application.
The whole situation felt chaotic and unstoppable. The best we thought we could do at the time was prepare people for the trauma. We implemented a certification program for Incident Commanders (IC). The IC was responsible for getting the right people in the (Slack) room; and then, liaising between the triage team and the rest of the organization.
To become IC certified, you had to be trained by an existing IC at the company. You had to run through a mock incident and demonstrate that you understood:
- How to identify the relevant teams.
- How to page the relevant teams, waking them up if necessary.
- How to start the "war room" Zoom call.
- How to effectively communicate the status of the outage and the estimated time to remediation.
This IC training and certification program was mandatory for all engineers. Our issues were very real and very urgent; and, we needed everyone to be prepared.
Over time, we became quite adept at responding to each incident. And, in those early days, this coalescing around the chaos formed a camaraderie that bound us together. Even years later, I still look back on those Zoom calls with a fondness for how close I felt to those that were there fighting alongside me.
But, the kindness and compassion that we gave each other internally meant nothing to our customers. The incidental joy that we felt from a shared struggle was no comfort to those that were paying us to provide a stable product.
Our Chief Technical Officer (CTO) at the time understood this. He never measured downtime in minutes, he measured it in lost opportunities. He painted a picture of customers, victimized by our negligence:
"People don't care about Service Level Objectives and Service Level Agreements. 30 minutes of downtime isn't much on balance. But, when it takes place during your pitch meeting and prevents you from securing a life-changing round of venture capital, 30 minutes means the difference between a path forward and a dead-end."
The CTO put a Root Cause Analysis (RCA) process in place and personally reviewed every write-up. For him, remediating the incident was only a minor victory—preventing the next incident was his real goal. Each RCA included a technical discussion about what happened, how we became aware of the problem, how we identified the root cause, and the steps we intended to take in order to prevent it from occurring again.
The RCA process—and subsequent Quality Assurance Items—did create a more stable platform. But, the platform is merely a foundation upon which the product lives. Most of our work took place above the platform, in the ever-evolving user-facing feature-set. To be certain, a stable platform is necessary. But, as the platform stabilized, the RCA process began to see a diminishing return on investment.
In a last ditch effort to drive better outcomes, a Change Control Board (CCB) was put in place. A CCB is a group of "subject matter experts" that must review and approve all changes being made to the product with the hope that naive, outage-causing decisions will be caught before they cause a problem.
Unfortunately, a Change Control Board is the antithesis of worker autonomy. It is the antithesis of productivity. A Change Control Board says, "we don't pay you to think." A Change Control Board says, "we don't trust you to use your best judgement." If workers yearn to find fulfillment in self-direction, increased responsibility, and a sense of ownership, the Change Control Board seeks to strip responsibility and treat workers as little more than I/O devices.
And yet, with the yoke of the CCB in place, the incidents continued.
After working on the same product for over a decade, I have the luxury of hindsight and experience. I can see what we did right and what we did wrong. The time and effort we put into improving the underlying platform was time well spent. Without a solid foundation on which to build, nothing much else matters.
Our biggest mistake was trying to create a predictable outcome for the product. We slowed down the design process in hopes that every single pixel was in the correct location. We slowed down the deployment pipeline in hopes that every single edge-case and feature had been fully-implemented and tweaked to perfection.
We thought that we could increase quality and productivity by slowing everything down and considering the bigger picture. But, the opposite is true. Quality increases when you go faster. Productivity increases when you work smaller. Innovation and discovery take place at the edges of understanding, in the unpredictable space where customers and product meet.
Eventually, we learned these lessons. The outages and incidents went from a daily occurrence to a weekly occurrence to a rarity. At the same time, our productivity went up, team morale was boosted, and paying customers started to see the value we had promised them.
None of this would have been possible without feature flags.
Feature flags changed everything.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4540
The Status Quo
There's no "one way" for organizations to build and deploy a product. Even a single engineer will use different techniques in different contexts. When I'm at work, for example, I use a Slack-based chatbot to trigger new deployments; which, in turn, communicates with Kubernetes; which, in turn, executes an incremental rollout of new Docker containers. But, in my personal life—on side projects—I still use FTP in order to manually sync files between my development environment and my production environment.
No given approach to web development is inherently "right" or "wrong". Some approaches do have advantages. But, everything is a matter of nuance; and, every approach is based on some set of calculated trade-offs. At work, I get to use a relatively sophisticated deployment pipeline because I stand on the shoulders of my brilliant teammates. But, when I'm on my own, I don't have the ability to create that level of automation and orchestration.
Though many different approaches exist, most build and deployment strategies do have one thing in common: when code is deployed to a production server, users start to consume it. Add a new item to your navigation and—immediately—users start to click it. Change a database query and—immediately—users start to execute it. Refactor a workflow and—immediately—users start to explore it.
We're decades beyond the days of shipping floppy disks and CD-ROMs; but, most of us still inhabit a state in which deploying code and releasing code are the same thing. Having users come to us (and our servers) allows us to respond to issues rapidly; but, fundamentally, we're still delivering a static product to our customers.
To operate within this limitation, teams will oftentimes commit temporary logic to their control flow in order to negotiate application access. For example, a team may only allow certain parts of an application to be accessed if:
- The user is connecting though the Virtual Private Network.
- The request is coming from a set of allow-listed IP addresses.
- The authenticated user has an internal company email address.
- The incoming request contains a secret HTTP
Cookievalue. - The incoming URL contains a special query-string parameter.
- The HTTP
User-Agentcontains a magic string.
I've used many of these techniques myself. And, they all work; but, they're all subpar. Yes, they allow internal users to inspect a feature prior to its release; but, they offer little else in terms of dynamic functionality. Plus, exposing the gated code to a wider audience requires changing the code and deploying it to production. Which, conversely, means that re-gating the code—such as in the case of a major bug or incident—requires the code to be updated and re-deployed.
These techniques often treat deployment as an afterthought. Meaning, they're typically implemented only after a feature has been completed and is ready for review. This implies that the feature was defined and developed in relative isolation.
This is referred to as the Waterfall Methodology. Waterfall Methodology comprises a set of product development stages that get executed in linear sequence:
- Analysis and requirements gathering.
- Graphic design and prototyping.
- Implementation.
- Testing and quality assurance (QA).
- Deployment to production.
- Maintenance.
Each one of these stages is intended to be completed in turn, with the outputs from one stage acting as the inputs to the next stage.
At first blush, the Waterfall Methodology is attractive because it looks to create structure and predictability. But, this is mostly an illusion. In the best case scenario, the timeline for such a project is grossly underestimated. In the worst case scenario, the engineering team builds the wrong product.
Years ago, I worked at a company that used the Waterfall Methodology. On one particular project for a data-management tool, the team carried out the requirements gathering, did some graphic design, and then entered the implementation phase as per usual. But, building the product took a lot longer than anticipated (which is standard even in the best case scenario). And, naturally, the client was very upset about the slipping release date.
Finally, after many delays and many heated phone calls and much triaging, the team performed their big reveal to the client. And, after walking through the product, the client remarked, "This isn't at all what I asked for."
It turns out, there was a large understanding gap in the requirements gathering phase. This understanding gap was then baked into the design process which was subsequently baked into the engineering process.
The client was furious about the loss of time and money with nothing to show for it. The engineers were furious because they felt that the client hadn't been forthcoming during the analysis phase (classic victim blaming). And, the product managers were furious because the project failed and reflected poorly on the firm.
This isn't a black swan event. Many of us in the product development space have similar stories. And, as an industry, we've come to mostly agree that the Waterfall Methodology is problematic; and, that Agile Methodology is the preferred approach.
The Agile Methodology takes the Waterfall Methodology, shrinks it down in scope, and repeats it over and over again until the work is complete. The cornerstone of an agile development workflow is a strong emphasis on "People over processes and tools" using a continual feedback loop:
- Build small.
- Show your work.
- Refactor based on feedback.
- Repeat.
If our team had been using an agile development workflow (in the earlier anecdote), success would have been achieved. The client would have seen early-on that the product was moving in the wrong direction and they would have told us. In turn, the design and engineering teams would have changed course and adapted to the emergent requirements. And, ultimately, all stakeholders would have been happy with the outcome.
The Agile Methodology is fantastic!
At least, it is within a greenfield project—one in which no prior art exists. But, as soon as you release a product to the customers, all subsequent changes are being made within a brownfield project. This is where things get tricky and expensive.
Agile Methodology has clear advantages over Waterfall Methodology; but, eventually, both approaches run into the same fundamental problem: deploying code to production is still a dangerous proposition. And, even with an agile approach, bad things will happen. And so, the fear creeps in; and soon, in an effort to protect themselves, even agile-minded teams start to fall back into old waterfall tendencies.
In hopes of leaving nothing to chance, the design process becomes endless. An eroding trust in the engineering team leads to a longer, more tedious QA period. Paranoia about outages means no more deploying on Fridays (or, perhaps, with even much less frequency). Test coverage percentage becomes a target. Expensive staging environments are created and immediately fall out-of-sync. A product manager creates a deployment checklist and arbitrarily makes load testing a blocking step.
The whole process becomes heavy and bloated and starts to creak and moan under the pressures—of time, of cost, of expectation—until, at some point, someone makes the joke:
Work would be great if it weren't for all the customers.
In an industry where customer empathy builds the foundation of all great products, wanting to work without customers becomes the sign of something truly toxic: cultural death.
This isn't leadership's fault. Or the fault of the engineers or of the managers or of the designers. This doesn't happen because the wrong technology stack was chosen or the wrong management methodology was applied. It has absolutely nothing to do with your people working in-office or being remote. This happens because a small seed of fear takes root. And then grows and grows and grows until it subsumes the entire organization.
Fear erodes trust. And, without trust we don't feel safe. And, if we don't feel safe, the only motivation that we have left is that of self-preservation.
This sounds dire; and it is; but it isn't without hope. All we have to do is address the underlying fear and everything else will eventually fall into place. This transformation takes time. But, it can be done; and, it starts with feature flags.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4541
Feature Flags, an Introduction
I've been working in the web development industry since 1999; and, before 2015, I'd never heard the term, "feature flag" (or "feature toggle", or "feature switch"). When my Director of Product—Christopher Andersson—pulled me aside and suggested that feature flags might help us with our company's downtime problem, I didn't know what he was talking about.
Cut to me in 2024—after 9 years of trial and error—and I can't imagine building another product or platform without feature flags. They have become a critical part of my success. I put feature flags in the same category as I do logs and metrics: the essential services upon which all product performance and stability are built.
But, it wasn't love at first sight. In fact, when Christopher Andersson described feature flags to me in 2015, I didn't see the value. After all, a feature flag is just an if statement:
if ( featureIsEnabled() ) {
// Execute NEW logic.
} else {
// Execute OLD logic.
}I already had control flow that looked like this in my applications (see The Status Quo). As such, I didn't understand why adding yet another dependency to our tech-stack would make any difference in our code, let alone have a positive impact on our downtime.
What I failed to see then was the fundamental difference underlying the two techniques. In my approach, changing the behavior of the if statement meant updating the code and re-deploying it to production. But, with feature flags, changing the behavior of the if statement meant flipping a switch.
That's it.
No code updates. No deployments. No latency. No waiting.
This is the magic of feature flags: having the ability to dynamically change the behavior of your application at runtime. This is what sets feature flags apart from environment variables, build flags, and any other type of deploy-time or dev-time setting.
To stress this point: if you can't dynamically change the behavior of your application without touching the code or the servers, you're not using "feature flags". The dynamic runtime nature isn't a nice-to-have, it's the fundamental driver that brings both psychological safety and inclusion to your organization.
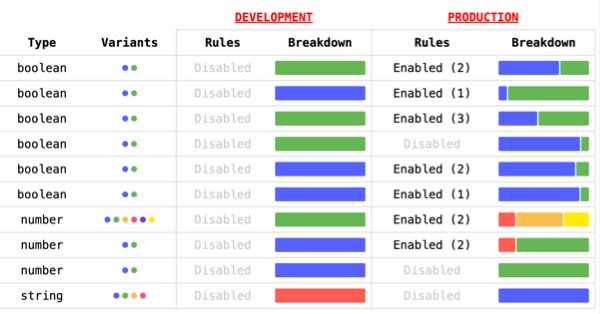
This dynamic nature means that in one moment, our feature flag settings look like this:

Which means that our application's control flow operates like this:
if ( featureIsEnabled() /* false */ ) {
// ... dormant code ...
} else {
// This code is executing!
}The featureIsEnabled() function is currently returning false, directing all incoming traffic through the else block.
Then, if we flip the switch on in the next moment, our feature flag settings look like this:

And, our application's control flow operates like this:
if ( featureIsEnabled() /* true */ ) {
// This code is executing!
} else {
// ... dormant code ...
}Instantly—or thereabouts—the featureIsEnabled() function starts returning true; and, the incoming traffic is diverted away from the else block and into the if block, changing the behavior of our application in near real-time.
But, turning a feature flag on is only half the story. It's equally important that a feature flag can be turned off. Which means that, should we need to in the case of emergency, we can instantly disable the feature flag settings:
Which will immediately revert the application's control flow back to its previous state:
if ( featureIsEnabled() /* false */ ) {
// ... dormant code ...
} else {
// This code is executing (( again ))!
}Even with the illustration above, this is still a rather abstract concept. To convey the power of feature flags more concretely, let's dip-down into the use-case that opened my eyes up to the possibilities: refactoring a SQL database query.
The efficiency of a SQL query changes over the lifetime of a product. As the number of rows increases and the access patterns evolve, some SQL queries start to slow down. This is why database index design is just as much art as it is science.
Traditionally, this type of refactoring involves running an EXPLAIN query, looking at the query plan bottlenecks, and then updating the SQL in an effort to better leverage existing table indices. The updated query code is then deployed to the production server. And, what the we hope to see is a latency graph that looks like this:
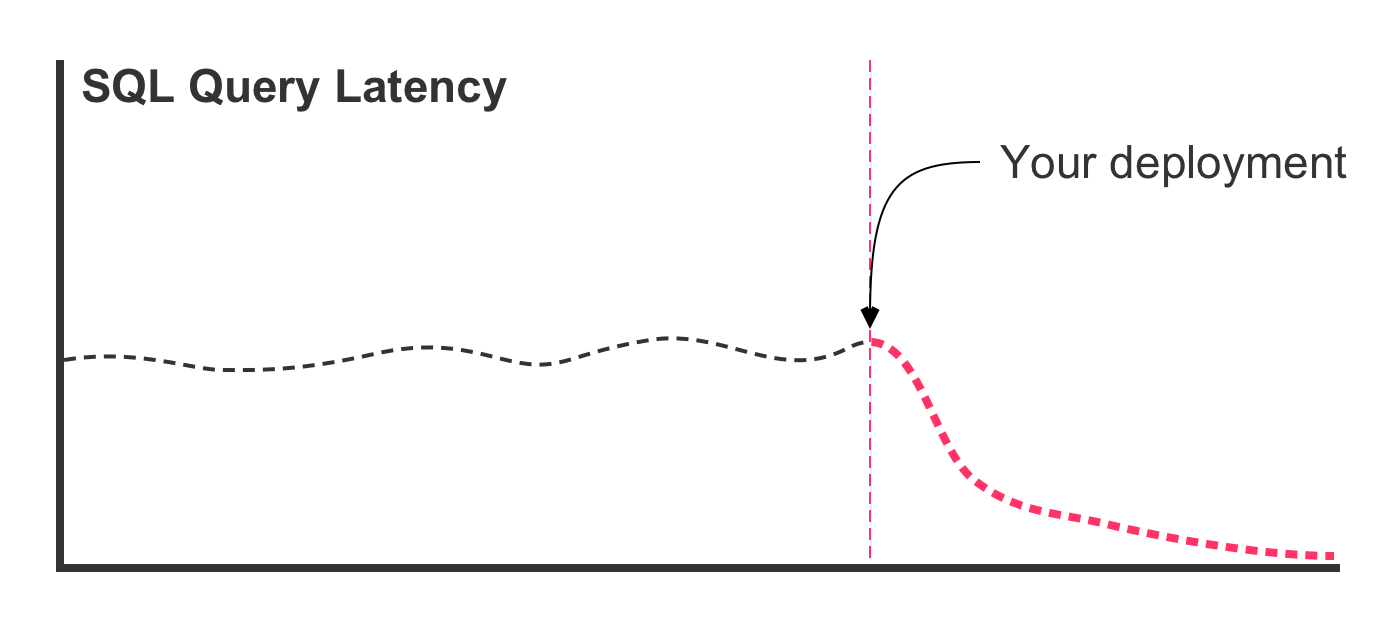
In this case, the SQL refactoring was effective in lowering the latency times. But, this is the best case scenario. In the worst case scenario, deploying the refactored query leads to a latency graph that looks more like this:
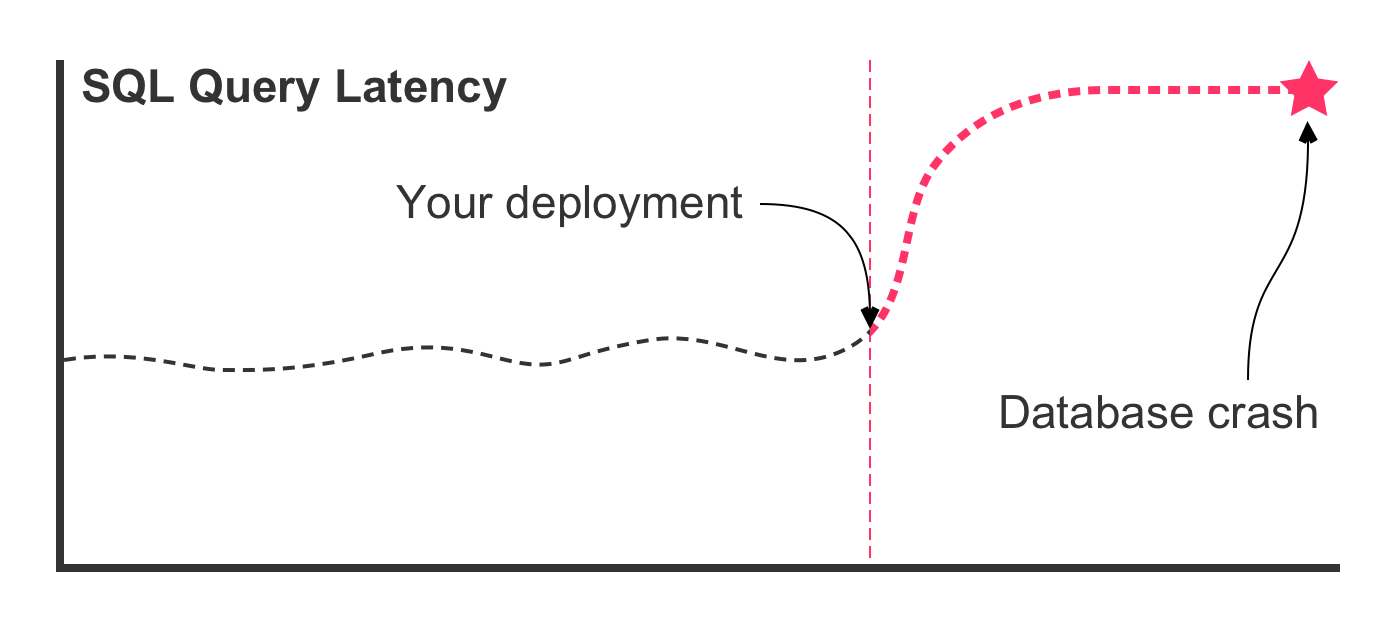
In this case, something went terribly wrong! The new SQL query that performed well in your development environment does not perform well in production. The query latency rockets upward, consuming most of the database's available CPU. This, in turn, slows down all queries executing against the database. Which, in turn, leads to a spike in concurrent queries. Which, in turn, starves the thread pool. Which, in turn, crashes the database.
If you see this scenario beginning to unfold in your metrics, you might try to roll-back the deployment. Or, you might try to revert the code and redeploy it. In either case, it's a race against time. Pulling down images, spinning up new nodes, warming up containers, starting applications, running builds, executing unit tests: it all takes time—time that you don't have.
Now, imagine that, instead of replacing your code and deploying it, you design an optimized SQL query and gate it behind a feature flag. Code in your data-access layer could look like this:
public array function generateReport( userID ) {
// Use new optimized SQL query.
if ( featureIsEnabled() ) {
return( getData_withOptimization( userID ) );
}
// Fall-back to old SQL query.
return( getData( userID ) );
}In this approach, both the existing SQL query and the optimized SQL query get deployed to production. However, the optimized SQL query won't be "released" to the users until the feature flag is enabled. And, at that point, the if statement will short-circuit the control flow and all new requests will use the optimized SQL query.
With a feature flag gating the new query, our worst case scenario looks strikingly different:
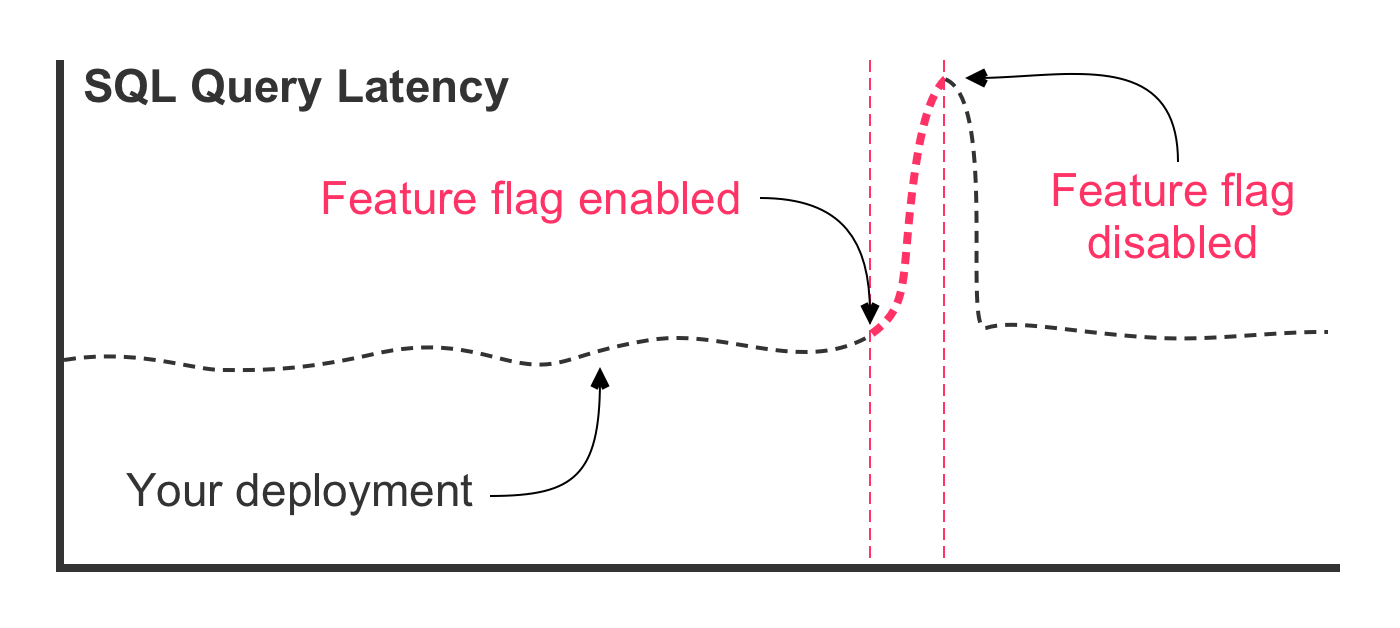
The same unexpected SQL performance issues exist in this scenario. However, the outcome is very different. First, notice (in the figure) that the deployment itself had no effect on the latency of the query. That's because the optimized SQL query was deployed in a dormant state behind the feature flag. Then, the feature flag was enabled, causing traffic to route through the optimized SQL query. At this point, that latency starts to go up. But, instead of the database crashing, the feature flag is turned off, immediately re-gating the code and diverting traffic back to the original SQL query.
You just avoided an outage. The dynamic runtime capability of your feature flag gave you the power to react without delay, before the database—and your application—became overwhelmed and unresponsive.
Are you beginning to see the possibilities?
Knowing that you can disable a feature flag in case of emergency is empowering. This alone creates a huge amount of psychological safety. But, it's only the beginning. Even better is to completely avoid an emergency in the first place. And, to do that, we have to dive deeper into the robust runtime functionality of feature flags.
In the previous thought experiment, our feature flag was either entirely on or entirely off. This is a vast improvement over the status quo; but, this isn't really how feature flags get applied. Instead, a feature flag is normally rolled-out incrementally in order to minimize risk.
But, before we can think incrementally, we have to understand a few new concepts: targeting and variants. Targeting is the act of identifying which users will receive a given a variant. A variant is the value returned by evaluating a feature flag in the context of a given request.
To help clarify these concepts, let's take the first if statement—from earlier in the chapter—and factor-out the featureIsEnabled() call. This will help separate the feature flag evaluation from the subsequent control flow and consumption:
var booleanVariant = featureIsEnabled();
if ( booleanVariant == true ) {
// Execute NEW logic.
} else {
// Execute OLD logic.
}In this example, our feature flag uses a Boolean data type, which can only ever represent two possible values: true and false. These two values are the variants associated with the feature flag. Targeting for this feature flag then means figuring out which requests receive the true variant and which requests receive the false variant.
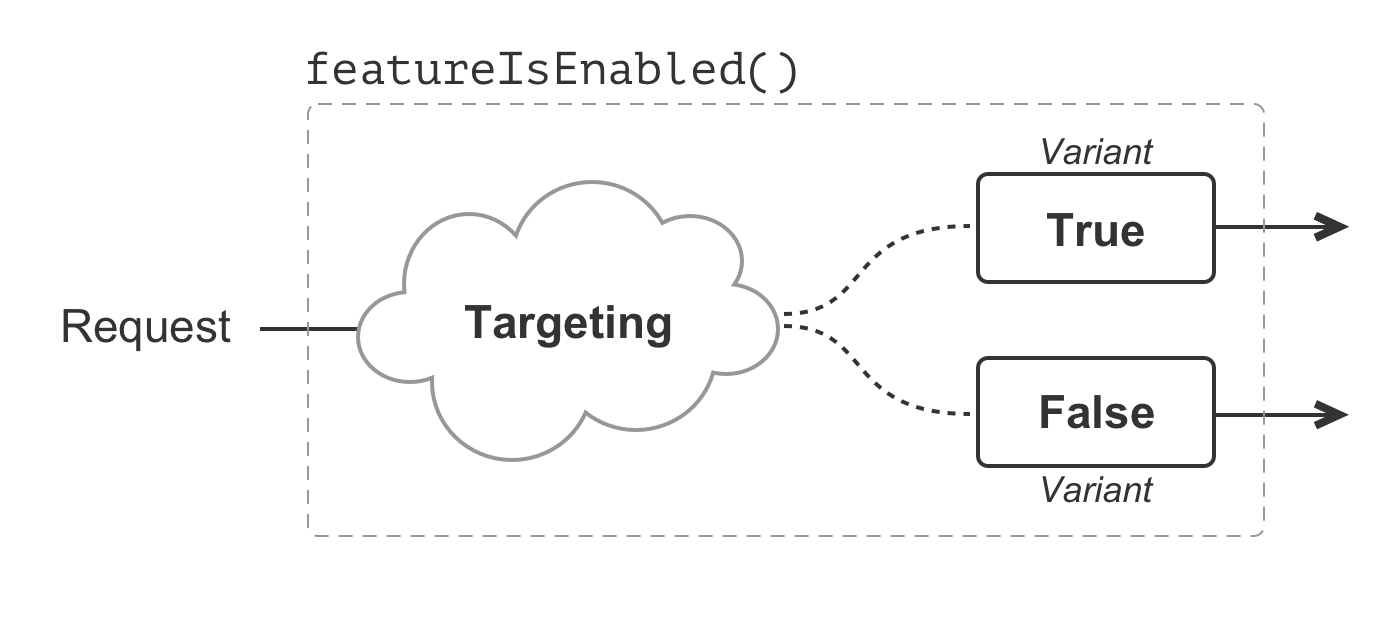
Boolean feature flags are, by far, the most common. However, a feature flag can represent any kind of data type: Booleans, strings, numbers, dates, JSON (JavaScript Object Notation), etc. The non-Boolean data types may compose any number of variants and can unlock all manner of compelling functionality. But, for the moment, let's stick to our Booleans.
Targeting—the act of funneling requests into a specific variant—requires us to provide identifying information as part of the feature flag evaluation. There's no "right type" of identifying information—each evaluation is going to be context-dependent; but, I find that User ID and User Email are a great place to start (for user-facing features).
Let's update our feature flag evaluation to include context about the current user:
var booleanVariant = featureIsEnabled(
userID = request.user.id,
userEmail = request.user.email
);
if ( booleanVariant == true ) {
// Execute NEW logic.
} else {
// Execute OLD logic.
}Throughout this book, I'm going to refer the request object as a means to access information about the incoming HTTP request. The request object has nothing to do with feature flags; and, is here only to provide the values that we need in order to illustrate targeting:
request.user- contains information about the authenticated user making the request. This will include properties likeidandemail(as shown above).request.client- contains information about the browser making the request. This will include properties likeipAddress.request.server- contains information about the server that is currently processing the request. This will include properties likehost.
Once we incorporate this identifying information into our feature flag evaluation, we can begin to differentiate one request from another. This is where things get exciting. Instead of our feature flag being entirely on for all users, perhaps we only want it to be on for an allow-listed set of User IDs. One implementation of such a featureIsEnabled() function might look like this:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
switch ( userID ) {
// Feature is enabled for these users only.
case 1:
case 2:
case 3:
case 4:
return( true );
break;
// Feature is disabled for everyone else by default.
default:
return( false );
break;
}
}Or, perhaps we only want the feature flag to be on for users with an internal company email address. One implementation of such a featureIsEnabled() function might look like this:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
if ( userEmail contains "@bennadel.com" ) {
return( true );
}
return( false );
}Or, perhaps we only want the feature flag to be enabled for a small percentage of users. One implementation of such a featureIsEnabled() function might look like this:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
// Reduce all user IDs down to a value between [0..99].
var userPercentile = ( userID % 100 );
if ( userPercentile <= 5 ) {
return( true );
}
return( false );
}In this case, we're using the modulo operator to consistently translate the User ID into a numeric value. This numeric value gives us a way to consistently map users onto a percentile: each additional remainder represents an additional 1% of users. Here, we're enabling our feature flag for a consistently-segmented 5% of users.
Note: We go into more depth about %-based targeting in a future chapter. Don't worry if this concept is confusing. Just accept, for now, that we can consistently target a percentage of our users.
We can even combine several different targeting concepts at once in order to apply more granular control. Imagine that we only want to target internal company users; and, of those targeted users, only enable the feature for 25% of them:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
// First, target users based on email.
if ( userEmail contains "@bennadel.com" ) {
var userPercentile = ( userID % 100 );
// Second, target users based on percentile.
if ( userPercentile <= 25 ) {
return( true );
}
}
return( false );
}User targeting, combined with a %-based rollout, is an incredibly powerful part of the feature flag workflow. Now, instead of enabling a risky feature for all users at one time, imagine a much more graduated rollout using feature flags:
- Deploy dormant code to production servers—no user sees any initial difference or impact within the application.
- Enable feature flag for your user ID.
- Test feature in production.
- Discover a bug.
- Fix bug and redeploy code (still only active for your user).
- Examine error logs.
- Enable feature flag for internal company users.
- Examine error logs and metrics.
- Discover bug(s).
- Fix bug(s) and redeploy code (still only active for internal company users).
- Enable feature flag for 10% of all users.
- Examine error logs and metrics.
- Enable feature flag for 25% of all users.
- Examine error logs and metrics.
- Enable feature flag for 50% of all users.
- Examine error logs and metrics.
- Enable feature flag for 75% of all users.
- Examine error logs and metrics.
- Enable feature flag for all users.
- Celebrate a successful feature release!
Few deployments will need this much rigor. But, when the risk level is high, the control is there; and, almost all of the risk associated with your deployment can be mitigated with a graduated rollout.
Are you beginning to see the possibilities?
So far, for the sake of simplicity, I've been hard-coding the dynamic logic within our featureIsEnabled() function. But, in order to facilitate the graduated rollout outlined above, this encapsulated logic must also be dynamic. This is, perhaps, the most elusive part of the feature flags mental model.
The feature flag evaluation process is powered by a rules engine. You provide inputs, identifying the request context (ex, User ID and User Email). And, the feature flag service then applies its rules to your inputs and returns a variant.
There is nothing random about this process—it's pure, deterministic, and repeatable. The same rules applied to the same inputs will always result in the same variant output. Therefore, when we talk about the dynamic runtime nature of feature flags, it is in fact the rules, within the rules engine, that change dynamically.
Consider the earlier version of our featureIsEnabled() function that ran against the userID:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
switch ( userID ) {
case 1:
case 2:
case 3:
case 4:
return( true );
break;
default:
return( false );
break;
}
}Instead of a switch statement, let's refactor this function to use a rule data structure that reads a bit more like a rule configuration. In this configuration, we're going to define an array of values; and then, check to see if the userID is one of the values contained within that array:
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
// Our "rule configuration" data structure.
var rule = {
input: "userID",
operator: "IsOneOf",
values: [ 1, 2, 3, 4 ],
variant: true
};
if (
( rule.operator == "IsOneOf" ) &&
rule.values.contains( arguments[ rule.input ] )
) {
return( rule.variant );
}
return( false );
}The outcome here is exactly the same, but the mechanics have changed. We're still taking the userID and we're still looking for it within a set of defined values; but, the static values and the resultant variant have been pulled out of the evaluation logic.
At this point, we can move the rule definition out of the featureIsEnabled() function and into its own function, getRuleDefinition():
public boolean function featureIsEnabled(
numeric userID = 0,
string userEmail = ""
) {
var rule = getRuleDefinition();
if (
( rule.operator == "IsOneOf" ) &&
rule.values.contains( arguments[ rule.input ] )
) {
return( rule.variant );
}
return( false );
}
public struct function getRuleDefinition() {
return({
input: "userID",
operator: "IsOneOf",
values: [ 1, 2, 3, 4 ],
variant: true
});
}Here, we've completely decoupled the consumption of our feature flag rule from the definition of our feature flag rule. Which means, if we wanted to change the outcome of the featureIsEnabled() call, we wouldn't change the logic in the featureIsEnabled() function. Instead, we'd update the getRuleDefinition() function.
But, everything is still hard-coded. In order to make our feature flag system dynamic, we need to replace the hard-coded data-structure with something to the effect of:
- A database query.
- A Redis
GETcommand. - A reference to a shared in-memory cache (being updated in the background).
Which creates an application architecture like this:
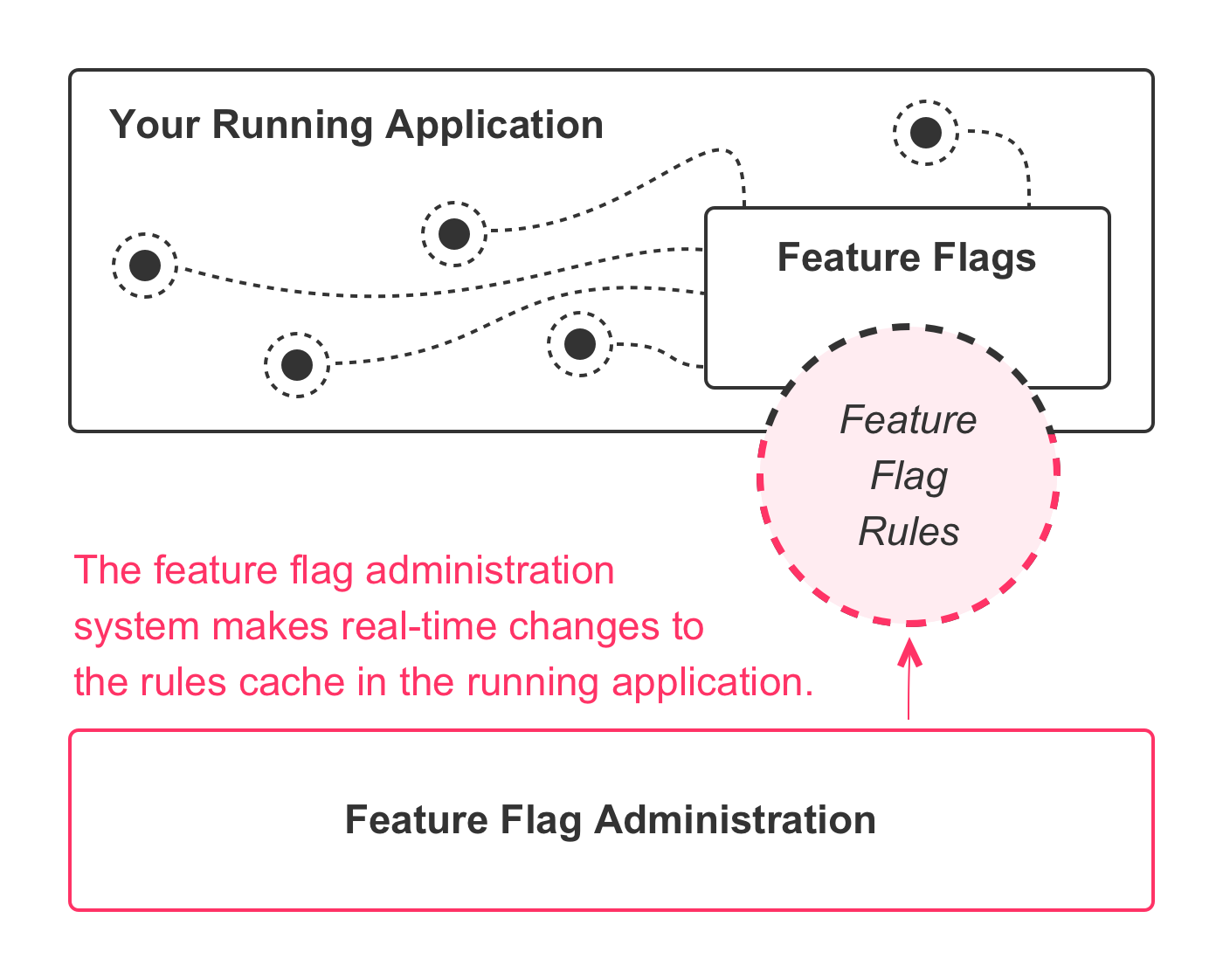
The implementation details will depend on your chosen solution. But, each approach reduces down to the same set of concepts: a feature flag administration system that can update the active rules being used within the feature flag rules engine that is currently operating in a given environment. This is what makes the dynamic runtime behavior possible.
At first blush, it may seem that integrating feature flags into your application logic includes a lot of low-level complexity. But, don't be put-off by this—you don't actually have to know how the rules engine works in order to extract the value. I only step down into the weeds here because having a cursory understanding of the low-level mechanics can make it easier to understand how feature flags fit into your product development ecosystem.
In reality, any feature flags solution that you choose will abstract-away most of the complexity that we've discussed. All of the variants and the user-targeting and the %-based rollout configuration will be moved out of your application and into the feature flags administration, leaving you with relatively simple code that looks like this:
var useNewWorkflow = featureFlags.getVariant(
feature = "new-workflow-optimization",
context = {
userID: request.user.id,
userEmail: request.user.email
}
);
if ( useNewWorkflow ) {
// Execute NEW logic.
} else {
// Execute OLD logic.
}This alone will have a meaningful impact on your product stability and uptime. But, it's only the beginning—the knock-on effects of a feature-flag-based development workflow will echo throughout your entire organization. It will transform the way you think about product development; it will transform the way you interact with customers; and, it will transform the very nature of your company culture.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4542
Key Terms and Concepts
Feature flags enable a new way of thinking about product development. This introduces some new concepts; and, adds nuance to existing ideas. As such, it's important to define—and perhaps redefined—some key terms that we use in this book:
Deploying
Deploying is the act of pushing code up to a production server. Deployed code isn't necessarily "live" code. Meaning, deployed code isn't necessarily being executed by your users—it may just be sitting there, on the server, in a dormant state. "Deployed" refers only to the location of the code, not to its participation within the application control flow.
A helpful analogy might be that of commented out code. If you deploy code that is commented out, that code is living "in production"; but, no user is actually executing it. Similarly, if you deploy code behind a feature flag and no user is being targeted, then no user is actually executing that deployed code.
Releasing
Releasing is the act of exposing deployed code and functionality to your users. Before the advent of feature flags, "deploying" code and "releasing" code were generally the same thing. With feature flags, however, these two actions can now be decoupled and controlled independently.
The ability to separate "release" from "deployment" is why we're here—it's the transformative feature of feature flags. It's why everything in your product development life-cycle is about to change.
Feature Flag
A feature flag is a named gating mechanism for some portion of your code. A feature flag typically composes an identifier (ex, new-checkout-workflow), a type (ex, Boolean), a set of variants (ex, true and false), a series of targeting rules, and a rollout strategy. Some of these details may vary depending on your feature flag implementation.
Variant
A variant is one of the distinct values contained within a feature flag configuration. A variant is what gets returned when a feature flag is evaluated within the context of a given request.
Each variant value is an instance of the Type represented by the feature flag. For example, a Boolean-based feature flag can only contain two variant values: true or false. On the other hand, a number-based feature flag can be configured to contain any set of defined numbers.
That said, at any given moment, the variants composed within a feature flag are finite, typically very few, and are always predictable. Entropy has no place in a feature flag workflow.
Targeting
Targeting is the mechanism that determines which feature flag variant is served to a given user. Targeting rules include both assertions about the requesting user and a rollout strategy. Targeting rules may include positive assertions, such as "the user role is Admin"; and, they may include negative assertions, such as "the user is not on a Free plan". Compound rules can be created by ANDing and ORing multiple assertions together.
The conditions within the targeting rules can be changed over time; however, at any given moment, the evaluation of the decision tree is repeatable and deterministic. Meaning, the same user will always receive the same variant when applying the same inputs to the same targeting rules.
Rollout
Rollout is an overloaded term in the context of feature flags. When we are discussing a feature flag's configuration, the rollout is the strategy that determines which variant is served to a set of targeted users. This is often expressed in terms of percentage. For example, with a Boolean-based feature flag, the rollout strategy may assign the true variant to 10% of targeted users and the false variant to 90% of targeted users.
When not discussing a feature flag's configuration, the term rollout is generally meant to describe the timeline over which a feature will be enabled within the product. There are two types of rollouts: immediate and gradual.
With an immediate rollout, the deployed code is released to all users at the same time. With a gradual rollout, the deployed code is released to an increasing number of users over time. So, for example, you may start by releasing a feature to a small group of Beta-testers. Then, once the feature sees preliminary success, you release it to 5% of the general audience; and then 20%; and 50%; and so on, until the deployed code has been "rolled-out" to all users.
Roll-Back
Just as with rollout, roll-back is another overloaded term in the context of feature flags. When we are discussing a feature flag's configuration, rolling back means reverting a recent configuration change. For example, if a targeted set of users is configured to receive the true variant of a Boolean-based feature flag, "rolling back" the feature flag would mean updating the configuration to serve the false variant to the same set of users.
When not discussing a feature flag's configuration, the term rolling back is generally meant to mean removing code from a production server. Before the advent of feature flags, if newly-deployed code caused a production incident, the code was then "rolled back", meaning that the new code was removed and the previous version of the application code was put back into production.
User
In this book, I often refer to users as the receiving end of feature flags. But, this is only a helpful metaphor as we often think about products in terms of customer access. In reality, a feature flag system doesn't know anything about users—it only knows about inputs. Most of the time, those inputs will be based on the requesting user. But, they don't have to be.
We'll explore this concept in more detail within our use-cases chapter (see Use Cases), but, for now, know that feature flag inputs can be based on any meaningful identifier. For example, we can use the server name to affect platform-level features. Or, we can use a static value (such as app) to apply the feature flag state to all requests uniformly.
Progressive Delivery
This is the combination of two concepts: deploying a feature incrementally and releasing a feature incrementally. This is—eventually—the natural state for teams that lean into a feature-flag-based workflow. This becomes "the way" you develop your products.
The mechanics of progressive delivery will be examined in much more depth within the life-cycle chapter (see Life-Cycle of a Feature Flag).
Environment
An environment is the application context in which a feature flag configuration is defined. At a minimum, every application has a production environment and a development environment.
A set of feature flags is shared across a set of environments; but, each environment is configured independently. A feature flag which is enabled in the development environment has no bearing on the same feature flag in the production environment. This is what allows a feature to be simultaneously enabled in the development environment and disabled in the production environment.
Feature Flag Administration
This is the application that your Developers, Product Managers, Designers, data scientists, etc. will use to create, configure, update, release, and roll-back feature flags. This administrative application is generally separated out from your product application; but, it doesn't have to be.
If you're buying a feature flag Software as a Service (SaaS) offering, your vendor will be building, hosting, and maintaining this administration module for you.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4543
Going Deep on Feature Flag Targeting
As web application developers, we generally communicate with the database anytime we need to gather information about the current request. These external calls are fast; but, they do have some overhead. And, the more calls that we make to the database while processing a request, the more latency we add to the response-time.
In order to minimize this cost, most feature flag implementations use an in-memory rules engine which allows feature flag state to be queried without having to communicate with an external storage provider. This keeps the processing time blazing fast! So fast, in fact, that you should be able to query for feature flag state as many times as you need to without having to worry about latency.
Aside: Obviously, all processing adds some degree of latency; but, the in-memory feature flag processing—when compared to a network call—should be considered negligible.
That said, shifting from a database mindset to a rules-engine mindset can present a stumbling block for the uninitiated. At first, it may be unclear as to why you need anything more than a User ID (for example) in order to do all the necessary user targeting. After all, in a traditional server-side context, said User ID opens the door to any number of database records that can then be fed into any number of control flow conditions.
But, when you can't go back to the database to get more information, all targeting must be done using the information at hand. Which means, in order to target based on a given data-point (such as a user's role or subscription plan), said data-point must be provided to the feature flag state negotiation process.
I find that a pure function provides a helpful analogy. A pure function will always result in the same output when invoked using the same inputs. This is because the result of the pure function is based solely on the inputs and whatever internal logic exists.
Consider this function:
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4544
The User Experience (UX) of Feature Flag Targeting
There are two groups of people affected by feature flag targeting: the people who use your product; and, the people who manage your feature flag system. Most of this book is about the former—I'd like to take a moment and talk about the latter.
When you first experiment with feature flags, you'll almost certainly use your database's primary keys as the value to target. After all, these database keys are the inputs we use most often in our application request processing. So, it's only natural to extend that mindset into the realm of feature flag targeting.
Which means, if you wanted to target an organization (ie, a semantic container for a cohort of users), you might use the organization's database ID:
{
variants: [ false, true ],
distribution: [ 100, 0 ],
rule: {
operator: "IsOneOf",
input: "companyID",
values: [ 1728 ],
distribution: [ 0, 100 ]
}
}In this case, we're targeting the companyID with value 1728. This will absolutely work. However, numbers have very little inherent meaning within your application. So, when a feature flag administrator goes to configure a feature flag and sees something to the effect of:
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4545
Types of Feature Flags
Feature flags vary in both the type of variants that they serve and in the way they're expected to operate within your application. Short-lived, Boolean-based features flags are likely to be the first type that you use. Their on/off state is easy to reason about; and, it closely aligns with the if statements that we already use in our application control flow. But, feature flags can be used—and abused—in many different ways.
Data Types
Any type of data that can be serialized for storage can be used in a feature flag. We think about feature flags as being a runtime concern—and they are primarily; but, they also have to be persisted across application restarts and sent over the wire. As such, we can only use data that is capable of being serialized and deserialized without the loss of information.
It's helpful to think of variant data as anything that can be represented as JSON. Data types such as strings, numbers, Booleans, objects, and arrays will therefore work naturally as a variant value since they each have native representations in JSON. Other data types such a date/time values can still be used; but, they will need to be translated (within your application code) into and out of JSON-compatible data-types.
Conceptual Types
Feature flags fall into two conceptual types. Mechanically, these two types are exactly the same—they differ only in how long they are intended to remain embedded within your application logic. I call these two types:
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4546
Life-Cycle of a Feature Flag
A complex system that works is invariably found to have evolved from a simple system that worked. The inverse proposition also appears to be true: a complex system designed from scratch never works and cannot be made to work. You have to start over, beginning with a simple system.
— John Gall (Gall's Law)
If you're used to taking a feature entirely from concept to finished code before ever deploying it to production, it can be hard to understand where to start with feature flags. In fact, your current development practices may be so deeply ingrained that the value-add of feature flags still isn't obvious—I know that I didn't get it at first.
To help illustrate just how wonderfully different feature flags are, I'd like to step through the life-cycle of a single feature flag as it pertains to product development. This way, you can get a sense of how feature flags change your product development workflow; and, why this change unlocks a lot of value.
For this thought experiment, let's assume that we're maintaining a collaborative task management product. Currently, users can create and complete tasks. But, they can only discuss these tasks offline. What we'd like to do is build a simple comment system such that each task can be backed by a persisted conversation.
My goal here isn't to outline a blueprint that you must follow in your own projects. My goal is only to shift your perspective on what is possible.
Flesh-out Work Tickets
Traditionally, when building a feature, tasks in your ticketing system represent work to be done. And, when using feature flags, this is also true. But, instead of arbitrary milestones, you need to start thinking about each ticket as a deployment opportunity.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4547
Use Cases
When your feature flags implementation can store JSON variants, it means that there's no meaningful limitation as to what kind of state you can represent. Which means, the use cases for feature flags are somewhat unlimited as well. As we saw in the previous chapter, using Boolean-type flags to progressively build and release a feature is going to be your primary gesture; but, the area of opportunity will continue to expand in step with your experience.
To help jump-start your imagination, I'd like to touch upon some of my use cases. This isn't meant to be an exhaustive list, only a list of techniques with which I have proven, hands-on experience.
Product: Feature Development for the General Audience
Building new features safely and incrementally for your general audience is the bread-and-butter of feature flag use cases. This entails putting a new feature behind a feature flag, building the feature up in the background, and then incrementally rolling it out to all customers within your product. We've already seen this in the previous chapters; so, I won't go into any more detail here.
This type of product feature flag is intended to be removed from the application once the feature has been fully released.
Product: Feature Development for Priority Customers
In an ideal world, new features get used by all customers. But, in the real world, sometimes you have to build a feature that only makes sense for a handful of high-priority customers. At work, we identify these customers as, "T100". These are the top 100 customers in terms of both current revenue and potential expansion.
The T100 cohort may contain specific individuals (such as the "thought leaders" and "influencers" within your industry). But, more typically, the T100 cohort consists of enterprise customers that represent large teams and complex organizations.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4548
Server-Side vs. Client-Side
In a multi-page application, the page is newly rendered after each browser navigation event. As such, there's no meaningful difference between a feature flag used on the server-side vs. one used on the client-side. Any changes made to a feature flag's configuration will propagate naturally to the client-side upon navigation.
With single-page applications (SPAs), the client-side code comes with life-cycle implications that require us to think more carefully about feature flag consumption. In a SPA, the client-side code—often referred to as a "thick client"—is composed of a relatively large HTML, CSS, and JavaScript bundle. This bundle is cached in the browser; and, navigation events are fulfilled via client-side view-manipulation with API calls to fetch live data from the back-end.
One benefit of loading the SPA code upfront is that—from a user's perspective—subsequent navigation events appear very fast. This is especially true if the client-side logic uses optimistic updates and stale while revalidate rendering strategies.
One downside of loading the SPA code upfront is that the version of the code executing in the browser may become outdated quickly. Each application is going to have its own usage patterns; but, for a business-oriented app, it's not uncommon for a SPA to remain open all day. Or, in the case of an email client, to remain open for weeks at a time.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4549
Bridging the Sophistication Gap
As you read through the use cases chapter, it may have occur to you that large, sophisticated companies have different ways of solving the same problems. For example, instead of using feature flags to implement rate limiting, a more sophisticated company might put that logic in an Application Load Balancer or a reverse proxy.
Or, instead of using feature flags to implement IP-blocking, a more sophisticated company might add reactive request filtering to a Web Application Firewall or dynamically update ingress routing rules.
Or, instead of gating code behind a feature flag, a more sophisticated company might adjust the traffic distribution across an array of Blue/Green deployment environments.
Or, instead of using feature flags to adjust log emissions, a more sophisticated company might change the filtering in their centralized log aggregation pipeline.
Large, sophisticated companies can do large, sophisticated things because they have massive budgets and hordes of highly-specialized engineers that are focused on building specialized systems. This allows them to solve problems at a scale that most of us cannot fathom.
But, this difference in relative sophistication isn't a slight against feature flags. Exactly the opposite! The difference is a spotlight that highlights the outsize value of feature flags—that we can use such simple and straightforward techniques to solve the same class of problems at a fraction of the cost and complexity.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4550
Life Without Automated Testing
People who say it cannot be done should not interrupt those who are doing it.
— George Bernard Shaw (misquoted)
This may be shocking to some engineers; but, I haven't written a test in years. And, I deploy code to production anywhere between 5 and 10 times a day.
Now, I'll caveat this by saying that I don't write and distribute library code for broad consumption—I maintain a large SaaS product over which the company has full end-to-end control. If your context is different—if the distance between your code and your consumer is vast—this chapter may not apply to you.
To be clear, I enthusiastically support testing! In fact, I thoroughly test every single change that I make to the code. Only, instead of maintaining a large suite of automated tests that run against the entire codebase, I manually test the code that I change, right after I change it.
Both automated testing and manual testing seek to create "correct" software. But, they accomplish this in two different ways. Automated testing uses tools and scripts to programmatically run tests on your application—without human intervention—comparing actual outcomes against expected results. Manual testing is the process of having a living, breathing, emotional human interact with your application in order to identify bugs, usability issues, and other points of concern that may or may not be expected.
While it's possible to build software without automated testing, manual testing isn't optional. At least, not in the product world. Manual testing is an essential part of the product development life-cycle. You make a change, you try it out, you make sure it works, you see how it feels, you adjust the code as needed.
Building a successful product isn't only about correctness—it's about creating an experience. And, you'll never create a great product unless experiencing the product is a core and consistent part of your product development workflow.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4551
Ownership Boundaries
Feature flags are an implementation detail for engineering teams. As such, each feature flag belongs to the engineering team that created it. If we were talking about any other low-level algorithmic decision, this sense of ownership would be self-evident; and, we wouldn't need to have this discussion. However, since feature flags can be both observed and configured outside of the application itself, it's easy for people to misunderstand where the boundaries must be drawn.
Who Can Manage a Feature Flag
Simple—the engineering team that implemented the feature flag is the only team that can manage the feature flag. Since feature flags are an implementation detail, only the implementing engineers have the necessary understanding of how changes to the configuration will impact the production system. These engineers know which database queries are involved; which API calls are being made; which areas of the application are being touched; and, most importantly, which error logs and performance dashboards need to be monitored during a release.
Your product manager doesn't have this information. Your designer doesn't have this information. Your data scientist doesn't have this information. Your growth engineers don't have this information. Your security and compliance officers don't have this information. No one other than the implementing engineers have a fully integrated understanding of the implications; and, therefore, no one other the implementing engineers should be touching the feature flag.
At the beginning of this book, we talked about feature flags as being little more than dynamic if statements. This code-oriented perspective can help bring the ownership boundaries into focus. The people who have permission to configure a feature flag are the same people that have permission to open your code and edit your if statements. And, if you wouldn't be comfortable with a given person jumping in and editing your code, you shouldn't be comfortable with that person jumping in and editing your feature flag configuration.
The exception to this rule involves open-ended, longer-term feature flags. For example, if a feature flag is being used to gate "T100" features or to act as a make-shift paywall (see Use Cases), targeting of the feature flag can be safely managed by customer-facing employees.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4552
The Hidden Cost of Feature Flags
Programmers know the benefits of everything and the trade-offs of nothing.
— Rich Hickey (creator of Clojure)
I believe that feature flags are an essential part of modern product development. But, every architectural choice represents a trade-off; and, so do feature flags. While they do create a lot of value, that value comes at a cost—both literal and figurative.
Whether you're building your own feature flags implementation or you're using a third-party vendor, feature flags cost money. You're either paying for development time and hosting if you build your own implementation; or, you're paying for usage and seats if you buy a managed solution.
We'll talk more about the financial trade-offs later (see Build vs. Buy). For now, I want to focus on the more hidden cost of feature flags.
In terms of developer ergonomics, feature flags create additional complexity in your code. By definition, they are spreading the business logic across two different systems: the application code and the runtime configuration. This makes it much more difficult to understand why the application is exhibiting a certain behavior. And, there's no possible way to know—at a glance—which conditional branch in the code should be executing.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4553
Not Everything Can Be Feature Flagged
Once you begin weaving feature flags into your product development life-cycle, it can become hard to imagine any other way of working. But, not every type of change can—or should—be put behind a feature flag. Sometimes, the level of effort isn't worth the added complexity.
At the end of the day, anything is possible when given the necessary time and resources. But, not everything is worth the cost of implementation. Feature flags should be relatively easy to use—they should be simplifying the amount of work you have to do in order to make changes in a production application. If the path forward isn't clear, it's possible that the change you're making isn't a good match for feature flags.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4554
Build vs. Buy
As engineers, we love to build! As such, it's completely natural to learn about feature flags and then think, "Yeah, I could build that." And, in fact, we did build a very simple implementation earlier in this book (see Going Deep on Feature Flag Targeting). But, building your own feature flags system is probably not a great use of your time (or your company's time).
Feature flags are deceptively simple. So much of what we see—the branching logic within our application code—is just the tip of the iceberg. There's much more below the surface that goes into keeping your feature flags available, reflecting configuration changes in near real-time, and allowing your team to manage feature flag state across multiple environments.
Assume that the cost of building your own implementation is going to be high—higher than you anticipate. And then, ask yourself if this kind of work generates a competitive difference for your company? Meaning, does building your own implementation give you a competitive advantage when compared to buying an existing implementation?
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4555
Track Actions, Not Feature Flag State
Data scientists and growth teams love to track everything. The assumption being that with enough data, user behaviors can be predicted and then manipulated. As such, when feature flags are introduced to an application, some people will want feature flag state to be included in the existing analytics data.
In my experience, this is a bad idea. For starters, it adds even more complexity to the code, especially if tracking happens in both the front-end and the back-end context. But, more than that, tracking feature flag state cuts against the grain of a feature flag's expected life-cycle.
Non-operational feature flags are intended to be transient: used briefly as a safe way to update the application; and then, removed when no longer needed. To track their state is to give feature flags a form of object permanence that they don't merit. This can dilute the sense of urgency that engineers should feel with regard to code quality.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4556
Logs, Metrics, and Feature Flags
In the early days of my career, my error-handling approach consisted of catching errors and then sending myself individual emails containing the error details. This was OK initially; but, it didn't scale well. Which I learned the hard way one morning when I arrived at my desk and found over 47,000 errors in my Inbox (due to a failing database connection).
Eventually, I learned about error logging and log aggregation services. And, suddenly, the idea of emailing myself an error message felt so naive and antiquated. The more I used logs, the more I came to realize just how powerful they were. And, soon thereafter, I started to view logging as a critical component in my application architecture.
Over time, I realized that I could use logs for more than just error messages. In fact, I could write anything I wanted in a log message. And so, I started to use logging as a way to record key user actions. When a user signed-up for an account, I logged it. When a user upgraded to a paid-plan, I logged it. When a user sent an invitation for collaboration, I logged it. I could then query the logs and get a sense of how the system was being consumed.
Then, I attended a web development meet-up group and learned about something called StatsD (created by Etsy). StatsD allowed an application to emit numeric values at a high rate without any added latency (due to the use of UDP as the underlying transport layer). These values could then be aggregated and graphed on a timeline, creating a visual heartbeat for any workflow within an application.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4557
Transforming Your Company Culture
At this point, I hope that you can see how feature flags make engineering work safer and more effective. In fact, I hope that you're downright eager to start using feature flags as soon as possible! And, I'm confident that once you start, your whole perspective on product development will be forever changed.
But, the technical benefits of feature flags are only the beginning. If you have customers or work on a team with other engineers, managers, and designers, there's much more value to be had.
The rest of this book deals with the inter-personal aspects of feature flags. And, I do not exaggerate when I say that feature flags can fundamentally change your company culture and the way your team operates. But, this change isn't easy; and it won't happen unless you step up and make it happen.
When you reduce feature flags down to the fundamentals, they're a simple concept powered by simple mechanics. But, these simple mechanics allow you to work small, build incrementally, and conditionally expose parts of your product. This, alone, is enough to open up a whole new world of opportunity and let you to ask the question, "What if?"
What if I could get better feedback about my work?
What if I could make it easier for developers to demonstrate value?
What if I could make it OK to experiment and take risks?
What if I could cultivate a strong connection to the product?
What if I could foster a strong sense of inclusion and belonging for both my team and my customers?
What if I could create more psychological safety for my team?
What if I could unblock my team and increase developer throughput?
What if I could increase agility and allow my team to meet emergent problems with optimistic enthusiasm?
What if I could make it easier for my organization to work together and manage expectations?
What if my day was driven by a sense of hope and purpose and not ruled by the fear of failure and judgement?
It's hard to believe that feature flags open up these lines of inquiry—after all, they're just dynamic if statements. But, these if statements have the power to transcend application code if you're willing to put in the work.
In the following chapters, I have three goals. First, I'm granting you permission to do the hard work that is needed to bring about change. Every culture has momentum and is resistant to change. Which means, any attempt to build a better organization will almost certainly be met with fear and opposition. Do not let this dissuade you from doing the right thing.
Second, I'm trying to outline tactical ways in which you can push your company culture in the right direction. This includes interactions with your team and with your customers.
Third, I'm trying to demonstrate why changing your approach to product development is ultimately a value-add for you, your team, your product, and your customers.
Feature flags are not a magic bullet—they won't automatically transform your company or your development methodologies. But, the opportunity is there—I promise you. And I hope that the rest of this book helps you find a path forward that works well for you and your company.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4558
People Like Us Do Things Like This
Company culture isn't defined by a set of principles or a mission statement; it isn't defined by the founder's vision; and, it cannot be mandated from the top. Company culture is defined by action; it is the byproduct of movement; and, it is born of guerrilla warfare.
It starts when people like you stand-up and say that to be here—to be on this team—it means something. And then, they act accordingly; demonstrating, with consistency, that people like us do things like this (1).
In a product company, I believe that our primary goal is to serve the customer. As engineers in a product company, I believe that people like us achieve this goal by shipping code. And, I believe that in order to ship code effectively, we must operate from a place of love and generosity.
Generosity means bringing our whole self to the work; and, leaning on our past experience in order to draw meaningful insight. It means trusting others to do the same. It means thinking "right" about our customers; and meeting them where they are, not only where we want them to be. It means working small and prioritizing throughput. It means unblocking each other and deploying to production, even when it scares us.
Generosity means saying, "this might not work"; and then, doing it anyway because something beautiful might happen; and because we believe that the possibility of beauty is far more important than our fear of failure and judgement.
This is not an easy way to exist. Which means that leading by example is also an act of generosity. As we make manifest our own beliefs, "we unconsciously give other people permission to do the same" (2).
People like us do things like that.
That is, people like us do things like that when it is possible. Only, many companies don't want us to operate from a place of love and generosity because such an endeavor implies risk. And, these companies have long regressed to a state in which risk avoidance is now the predominant motivator.
But, a company isn't a thing unto itself—a company is made of people. And, if we consider these people in the context of Maslow's Hierarchy of Needs, it's logical that a zeitgeist of fear will completely debase a company's culture. According to Maslow, people cannot go beyond themselves until their own basic needs for psychological safety are being met.
That's what makes feature flags so exciting—so rich with possibility! Feature flags diminish risk and help build psychological safety throughout the entire organization. This psychological safety gives everyone an opportunity to take action with virtuous intent. Over time, these actions will create a movement. And this movement will, eventually, transform your company culture.
1 From "People Like Us Do Things Like This" by Seth Godin.
2 From "Our Deepest Fear" by Marianne Williamson.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4559
Building Inclusive Products
The hard part about the idea of "minimum viable product," for me, is you don't know what "minimum" is, and you don't know what "viable" is.
— Ben Silbermann (co-founder of Pinterest)
In the digital product space, an EPD (Engineering, Product, Design) organization, is often described as a partnership. At work, we even referred to this as the three-legged stool—a metaphor which depicts each leg/department as being an equally important part of the overall product design process.
But, this is an idealized version of reality. More often, the EPD organization is built like a Totem pole; with Product at the top, Design in the middle, and lowly Engineering down at the bottom. This is much less like a partnership and much more like an assembly line.
Caveat: In my career as an engineer, the interplay between Product and Design has always been a bit of a black box. As such, I mostly speak about this process from the engineering perspective. And, I tend to think about Product and Design as being a single unit.
In this model, Engineering is handed a set of specifications (hopefully) in the form of an interactive prototype. Engineering then comes up with an estimate as to how long an implementation might take. Product then argues with the Engineering team, asserting that said estimate is completely absurd and needs to be cut in half. The Engineering team capitulates in an effort to keep the peace (with rationalizations about it only being an estimate). And then, when the Engineering team inevitably fails to meet the estimated due-date, they are reprimanded. And, the Product team becomes increasingly convinced that the Engineering team is the cause of all the company's problems.
If you're not familiar with this story, consider yourself lucky—you are in the minority. These are the trying conditions under which many teams operate.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4560
An Opinionated Guide to Pull Requests (PRs)
Everything in this chapter is predicated on the notion that getting our code into production is the single most important thing that we do as product engineers. Our code creates value for the customer. And, releasing that code incrementally—using feature flags—creates a fly-wheel of feedback that leads to more inclusive products; and, creates the psychological safety that the EPD organization needs in order to iterate effectively. But, this value is only ever realized after our code reaches production and becomes available for consumable.
Deploying code is, therefore, an act of love and generosity; both for our internal team and for the external customers. The entire process preceding deployment must be optimized in order to maximize the value that we deliver—as engineers—to the people that we're serving.
There are many steps that need to be completed when taking a project from conception to deployment. If any one of these steps creates a bottleneck, the entire process is delayed; and, as a result, the customers suffer.
More often than not, the slowest and most unpredictable step in this process is the pull request review. It's not uncommon for a PR to remain open for days; and, every now and then, I hear from an engineer who waited weeks for their code to be reviewed and approved.
Frankly, this is unacceptable. If a PR remains open for more than 15 minutes, your process has failed you. And, more to the point, your process has failed the customer.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4561
Removing the Cost of Context Switching
In software design, there are two types of complexities: essential and accidental. Essential complexity represents the fundamental nature of a problem. There is no way to get around or reduce this complexity as it is born of the problem itself. Accidental complexity, on the other hand, is self-imposed. It is the complexity that we unnecessarily add to the software through inexperience, insufficient planning, technical limitation, and "résumé-driven development".
When working within the confines of the waterfall methodology, the scope of the project often becomes part of the project's essential complexity. Since every aspect of a waterfall project must be developed, tested, revised, tweaked, polished, and approved before it can be deployed, product engineers are forced to hold a tremendous amount of information in their head at all times.
This complexity of scope doesn't have to become "essential". However, when engineers don't have the technological means to safely and incrementally deploy work (via feature flags), the scope of the project takes on a de facto gravity that gives it an essential expression within the overall complexity.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4562
Measuring Team Productivity
Fuzzy math over time still shows trends.
— Mike Maughan (podcast, No Stupid Questions)
When your team uses feature flags to work small and build incrementally, what you end up with is a culture of shipping. In this culture, deployments become the heartbeat of the system; and, a bellwether of health. When a team is functioning well, its engineers ship often. And, when a team is having trouble, shipping slows down or becomes a rarity.
Deployments, therefore, act as a metric that can proxy team health and productivity. There's no absolute value here that indicates health; but, deviations from the baseline will reveal truths about the team, its engineers, and their relationship to the rest of the organization.
For example, if an engineer hasn't shipped code in a day or two, it might be an indication that they are stuck. Perhaps the project requirements are unclear; and, they're afraid to ask questions. Or, perhaps the work is too complex; and, they're having trouble decomposing the work into small, incremental steps.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4563
Increasing Agility With Dynamic Code
In traditional project management, each feature is developed entirely within a development environment. And, each feature is only ever released to production once it is 100% complete, reviewed, polished, and approved. This has a negative impact on the quality of the feature; but, it also has a negative impact on the team itself.
Until a feature is released, it only represents a potential value for the customer. Which is a pleasant way of saying that the feature is entirely worthless until it is deployed to production.
This creates a challenging dynamic for the team because it means that the engineers on the team can only demonstrate value once the feature is completed and deployed. In such an environment, all interruptions come with real psychological discomfort: every time an engineer stops what they're doing, they see the finish-line—and their moment to shine—slipping further and further into the future.
And so, the team begins to view work as a competitive, zero-sum game. Cross-team collaboration—once viewed as an act of generosity—is now met with a residue of resentment. To protect itself, the team doubles-down on process and uses the existing roadmap as a shield that deflects all incoming requests. Soon, the team becomes so sclerotic—so unwilling to adapt—that even trivial product changes must be scheduled months in advance.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4564
Product Release vs. Marketing Release
One of the most frustrating mistakes that I repeatedly see within an organization is the conflation of a product release with a marketing release. A product release is the exposure of new functionality to users within the product. A marketing release is the announcement of product updates to the rest of the world.
There is no reason that these two releases need to happen at the same time. In fact, attempting to combine the product release and the marketing release is misguided.
Consider the amount of information that your team has about a feature that it is building. As we discussed in the life-cycle chapter (see Life-Cycle of a Feature Flag), we continue to gather new information throughout the product development life-cycle. This leads up to and includes the release of the feature to the users.
Which means, the product release will necessarily represent an incomplete version of the feature. This is OK when your goal is to co-create an inclusive product with customers that are already enrolled in the product journey. But, this is not great if you're about to share your new wares with the rest of the world.
Instead, you should be releasing your product continually, allowing individual features to evolve in production with your customers. Then, at some point in the future, release a set of features to the rest of the world in some razzle-dazzle-infused marketing moment.
Which is to say that feature flags are not in conflict with marketing releases; because, product releases are not in conflict with marketing releases. In fact, you can use feature flags for both product releases and marketing releases (so long as they are different feature flags owned by different teams).
As product engineers, you should not expect the marketing team to think about this. The marketing team's job is to market the product—not to manage the product engineers. It is the sole responsibility of the product engineers to enforce a process internally that ensures the success of the product.
This may mean pushing back against deadlines. Or, at the very least, negotiating over scope. This can be uncomfortable. But, remember that what you're doing is choosing to build a culture that does right by the customer and creates psychological safety for the team. This is an act of love and generosity.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4565
Getting From No to Yes
It's not enough; but not enough is better than nothing.
— Phillip Atiba Goff
In an organization where features must be fully completed before being deployed, the people who say "No" to a deployment might characterize themselves as "protecting" the customer and the customer experience. By holding back until a feature is "perfect", "lovable", and beyond reproach, these gatekeepers might even position themselves as being the true champions of the customer; and, the ones keeping the rest of the organization under control.
But, saying "No" starts to feel very different when you're using feature flags to incrementally deploy a feature to production. Unlike a feature deployment, which represents a potentially large amount of coordinated work, a feature release—using feature flags—is nothing more than a flip of the switch. This alters the social dynamic within the organization.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4566
What If I Can Only Deploy Every 2 Weeks?
Creating a culture of shipping is going to be a problem if your company only allows for a single, coordinated deployment ever N number of weeks. If that's the case, I would suggest taking time to understand where that constraint is coming from. It might be fear-based. But, it might be part of a contract; or, part of some security and compliance requirement.
If the constraint is fear-based, you have some wiggle room. You have an opportunity to demonstrate that building products with feature flags—and working small and shipping more often—is actually safer. This won't be an easy argument to make, given the context; but, if you're reading this book, I suspect that you're the right type of person to lead this effort.
Perhaps you can start by getting permission to experiment with work that is outside of the main product-suite. Or, perhaps you can apply this approach to internal dashboards where bugs aren't considered a mission critical issue.
Remaining chapter content available in purchased book (buy this book).
Have questions? Let's discuss this chapter: https://bennadel.com/go/4567
I Eat, I Sleep, I Feature Flag
When I first started toying around with web development in the 90s, I was uploading static HTML files to GeoCities. It was thrilling to take an idea that was only in my head and turn it into something that I could share with the world. I felt connected to the human experience in a way that didn't previously seem possible.
After a while, however, I came to understand that operating in isolation was very limiting. From my experience using online message boards, I knew that the real magic happened through human interaction. But, I didn't know how to create connections using static HTML. Even with JavaScript sprinkles, the best I could do was move objects around the screen and perform dynamic image roll-overs.
That said, I was hooked! I knew that this was what I wanted to do with my life. And so, in 1999, I got my first web development internship at Koko Interactive, a digital agency in NYC that created online products and enterprise extranets. It was there that I learned about ColdFusion, CFML, and databases.
Having a dynamic back-end with a database was transformative! Databases opened up a whole new world of opportunity—not only to foster human connection but also to provide services that literally change the way people live and work.
I share this story with you in order to find some common ground. Since you're reading this book, I'm going to assume that some of my origin story matches yours. And, that you too have experienced the step function which is data persistence. And, that—like me—you can't really imagine building a robust product offering without a back-end database.
Holding that thought in mind, I want to say that feature flags represent the same kind of step function. They work through a different mechanism; but, the transformative power of feature flags is similar in magnitude to the transformative power of databases. And, in that same vein, I can no longer imagine building a robust product offering without feature flags.
They really do change everything, at every level of the organization. And, I truly believe that the products you develop with feature flags will be more inclusive, more stable, more focused, and more successful.
Have questions? Let's discuss this chapter: https://bennadel.com/go/4568